
NLU Engines
Q&A and Task bots use NLU (Natural Language Understanding), which in turn uses the power of machine learning to determine the intent of consumer statements. Swiftmatch, RASA, and Mindmeld are three NLU engines used to assess the intent from the consumer inputs and respond with an accurate response. Swiftmatch is a fast, lightweight training engine that supports multiple languages, whereas RASA is a leading open-source conversational AI framework. Mindmeld (Beta) is an advanced conversational AI framework that produces quality conversational flows and offers various NLU capabilities.
When compared to Swiftmatch, RASA requires more training data to attain high accuracy. Developers can use the NLU engine option on the Articles tab of Q&A bots and the Training tab of Task bots to switch from one engine to another to gauge the bot performance with different engines. Changing the training engine will update the algorithm in the bot’s corpus. Whenever the training engine is changed, the bot must be trained. After training, the inference will be in accordance with the trained model created by the new engine. You can analyze the differences by viewing the similarity scores for transactions in Sessions and by using one-click testing for different engines.
Developers can also test the bot and re-configure the thresholding scores in the ‘Handover and inference’ section of the Bot configuration page, after switching the engine. The scores for the RASA threshold tend to be inversely proportional to the number of intents, i.e., a bot with a large number of intents (100+) will have a relatively lower score under the ‘score below which fallback is shown’ configuration in inference.
Switching between the training engines
Use this procedure to switch between the NLU engines.
- Select the Q&A bot of which you want to change the training engine.
- Click Articles. The Knowledge base screen appears.

- Click NLU Engine on the right side of the page. The Change training engine window appears

Change training engine in Q&A bot
Note: By default, the NLU engine is set to Swiftmatch for the newly created bots.
-
Select the training engine to train the bot. Possible values:
• RASA (Beta)
• Swiftmatch
• Mindmeld (Beta) -
Specify this information in the Inference section
| Field | Description |
|---|---|
| Score below which fallback is shown | The minimum confidence needed for a response to be displayed to users, below which a fallback response will be shown. |
| The difference in scores for partial match | Defines the minimum gap between confidence levels of responses to clearly display the best match below which a partial match template will be shown |
| No. of results to store for each message | The number of articles for which bot’s calculated confidence scores will be displayed under transaction info in sessions. Note: The number of results to display in the Algorithm section of the Sessions screen has now been limited to 5. The top n results (1=<n=<5) will be available in message transcript reports of Q&A and task bots as well as in the ‘Algorithm results’ section of Transaction info tab in Sessions. |
- Click to expand the Advanced settings section.
Note:
Developers can set different threshold scores for different NLU engines to determine the lowest score that is acceptable to display the bot response.

Advanced settings for Swiftmatch in Q&A bots

Advanced settings check boxes for Rasa and Mindmeld in Q&A bot
Expand contractions
English contractions in the training data can be expanded to the original form along with the terms in the incoming consumer query for greater accuracy. Example: ‘don’t' is expanded to ‘do not’. If this check box is selected, the contractions in the input messages are expanded before processing. This capability is supported for all three NLU engines.
Remove stopwords
‘Stopwords’ are function words that establish grammatical relationships among other words within a sentence but do not have lexical meaning on their own. When these stopwords such as articles (a, an, the, etc.), pronouns (him, her, etc.) and so on are removed from the sentence, the machine learning algorithms can focus on words that define the meaning of the text query by the consumer. If this check box is selected, the ‘stopwords’ are removed from the sentence at the time of training as well as inference. This NLU engine capability is supported only for Swiftmatch.
Wordform expansion
Expand training data with wordforms such as plurals, verbs, and so on, along with the synonyms embedded in the data. This capability is supported only for Swiftmatch.
Synonyms
Synonyms are alternative words used to denote the same word. If this check box is selected, common English synonyms for words in the training data get auto generated from to recognize the consumer query precisely. For instance, for the word garden, the system generated synonyms can be a backyard, yard, and so on. This NLU engine capability is supported only for Swiftmatch.
Wordforms
Wordforms can exist in various forms such as plurals, adverbs, adjectives, or verbs. For instance, for the word “creation”, the wordforms can be created, create, creator, creative, creatively, so on. If this check box is selected, the words in the query are created with alternative forms of words and are processed to give an appropriate response to consumers.
Remove special characters
Special characters are the non-alphanumeric characters that have an impact on inference. For example, Wi-Fi and Wi Fi are considered differently by the NLU engine. If this check box is selected, the special characters in the consumer query are removed to display an appropriate response. This NLU engine capability is supported only for Swiftmatch.
Spellcheck in inference
Text correction library identifies and corrects the incorrect spellings in the text before inference. This capability is supported for all three engines only if the Spellcheck in inference check box is selected.
- Click Update to change the algorithm in the bot's corpus.
- Click Train. Once the bot is trained with the selected training engine, the Knowledge base status changes from Saved to Trained.
Note: You can Train the bot with RASA and Mindmeld only if all the articles have at least two utterances.


Training
Once all the desired articles are created, users should train their bot and make it live to test and deploy it. To train the bot with its current corpus, click the Train button on the top right. This should change the status to ‘Training’.

Once the training is complete, the status changes to ‘Trained’. User can click the reload icon next to 'Training' to retrieve the current training status.

At this point, users can click the Make Live button to make the trained corpus live and test it in Webex Bot Builder shareable preview or on external channels where the bot is deployed.

Vector Model
Users can now select their preferred vector models as a part of the advanced engine settings in the Swiftmatch NLU engine. Selection is possible between two options – Utterance level vs Article level vectors. In our continued push to improve the accuracy of our NLU engines, we experimented with using article level vectors as opposed to the older model of using utterance level vectors and found article level vectors improve accuracy in most cases. Please note the article level vectors will be the new default value for vectorization for new single lingual bots and for multilingual bots article level matches will be supported only when the multi-lingual model is Polymatch.
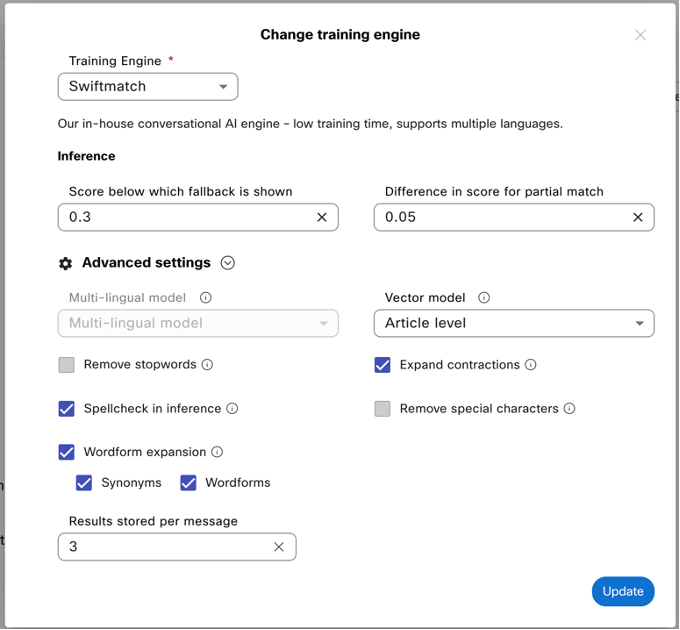
Vector model selection
Users can check the information on vector model that was present at the time of an inference in the session’s ‘other info’ section.
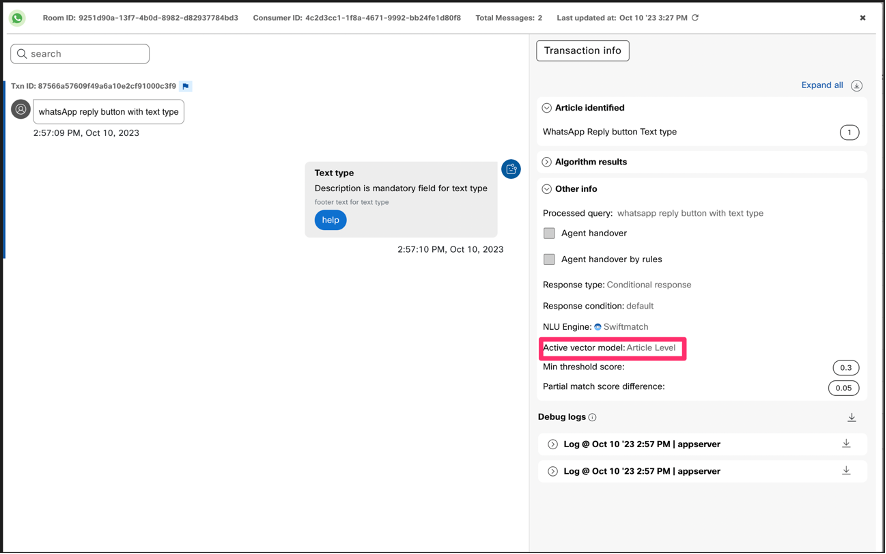
Vector model information in sesssions
Multi-lingual support using mindmeld
Mindmeld engine now supports multi-lingual operations. The following languages are supported -
- Arabic
- Bulgarian
- Catalan
- Croatian
- Danish
- Dutch
- English
- Estonian
- Finnish
- French
- Georgian
- German
- Greek
- Hebrew
- Hindi
- Hungarian
- Indonesian
- Irish
- Italian
- Korean
- Lithuanian
- Macedonian
- Malayalam
- Mongolian
- Nepali
- Norwegian Bokmål
- Persian (Farsi) (not to be added to task bots)
- Polish
- Portuguese
- Romanian
- Russian
- Spanish
- Swedish
- Turkish
- Ukrainian
- Vietnamese
Updated 3 months ago